📌 공부 계기
추가적인 도커 공부를 위해 유튜브 따배도 도커 시리즈를 보면서 정리해 봅니다.
목차
📍8-1. Docker Container Storage : 이론
1️⃣ 컨테이너 볼륨이 뭐에요?
컨테이너 이미지는 readonly이다
컨테이너 이미지를 컨테이너로 돌리게 되면 RW (ReadWrite) 레이어가 추가되고 컨테이너에 추가되는 데이터들이 이곳에 저장되게 된다.
이처럼 기존의 readonly 레이어에 readwrite 레이어를 올려 마치 하나인 것처럼 관리하고 보여주게 되는데
이를 union file system(다른말로 overlay) 이라고 한다.
이렇게 하나처럼 운영되는 컨테이너는 컨테이너를 삭제하면 rw레이어 데이터까지 지워버리게 된다.
데이터를 보존해야하는데!
그래서 컨테이너가 제공하는 기능이 바로 볼륨이다.
컨테이너 rw 레이어의 디렉토리 경로와 호스트 저장소 디렉토리를 연결하여 rw레이어에 쌓일 데이터를 호스트 컴퓨터 저장소에 쌓이게 함으로써 컨테이너 삭제시에도 데이터를 보존할 수 있게 한다.
이렇게 연결하는 걸 볼륨 마운트라고 한다. 명령어로는 run시 v옵션으로 가능하다.
docker run [-v 호스트디렉토리:컨테이너디렉토리] <이미지명:태그>
2️⃣ 데이터를 보존하고 싶어요
-volume 옵션 사용
| -v | <host path> | : | <container mount path> | 기본 방식 | ||
| -v | <host path> | : | <container mount path> | : | <read write mode> | *** |
| -v | <container mount path> | 호스트의 /var/lib/docker 밑에 UUID 디렉토리 아래로 저장시켜준다. | ||||
*** 보안을 위해 컨테이너는 오직 호스트 경로의 데이터만 읽어오고 컨테이너에 쌓이는 게 호스트에 영향이 가지 않게 하는 것은 read write mode 자리에 ro를 (readonly)를 써주면 된다.
3️⃣ 컨테이너끼리 데이터 공유 가능한가요?
하나의 컨테이너 디렉토리와 호스트 디렉토리를 연결하여 데이터를 쌓고,
또 다른 컨테이너 디렉토리와 그 호스트 디렉토리를 연결하여 데이터를 공유하면
두 컨테이너가 같은 호스트 디렉토리를 바라보게 되어 컨테이너끼리 데이터 공유가 가능하다.
ex)
컨테이너가 web content를 만들어 저장하면 다른 webserver 컨테이너가 그 생성한 web content 파일을 가지고 실행을 할 수가 있다. 클라이언트는 webserver 컨테이너에 접속하는 것 만으로도 web content 컨테이너가 제공하는 것과 webserver가 제공하는 것을 다 누릴 수 있게 된다.
📍8-2. Docker Container Storage : 실습
1️⃣ mysql DB data 영구 보존하기
1) MySQL 컨테이너 생성 및 실행하기
*** MySQL DB 실행할 때는 관리자의 패스워드를 함께 지정해줘야한다.
해당 경로가 없으면 디렉토리를 자동으로 생성함
# docker run [-d] [--name 컨테이너명] [-v 호스트경로:컨테이너경로] [-e 환경변수=값] <이미지:태그>
docker run -d --name db -v /dbdata:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=pass mysql:latest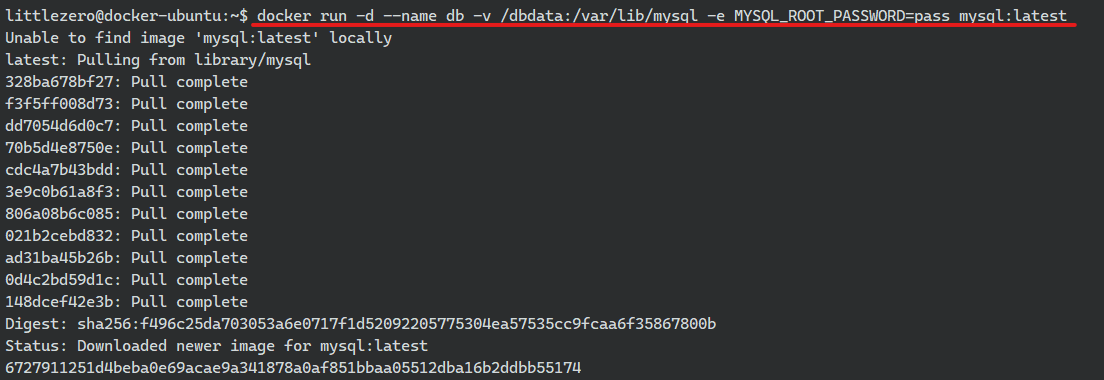
2) 컨테이너 안의 MySQL에 접속해서 데이터베이스 생성해보기
컨테이너를 터미널로 연결해서 mysql에 접속
그리고 데이터베이스 확인까지!
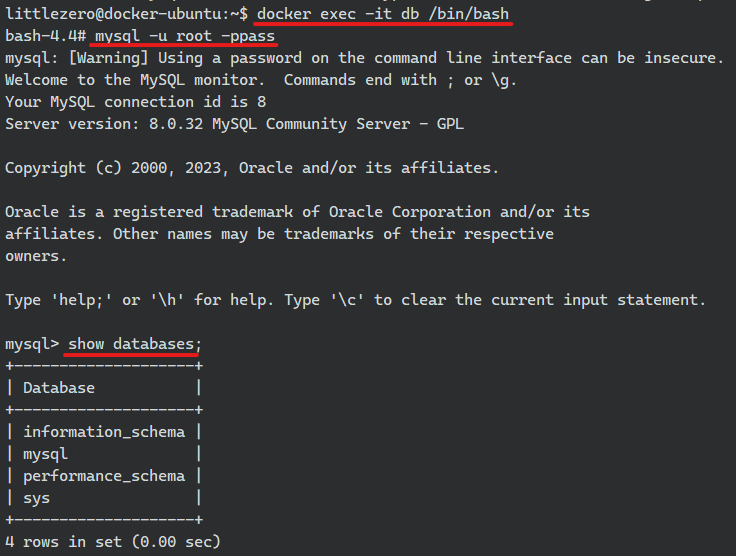
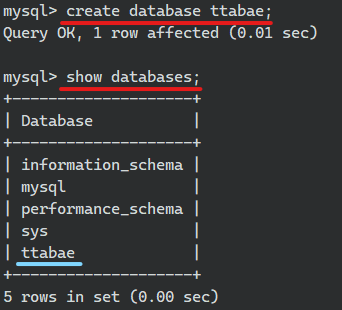
컨테이너 안에 ttabae라는 DB를 생성했으니 호스트 연결된 경로에도 ttabae가 연결됬는 지 확인하면 된다.
호스트 경로에 들어가 조회하니 ttabae가 있는 것을 확인!

3) 컨테이너를 삭제했을 때도 남았는지 확인

4) 호스트 경로 없이 컨테이너 경로만 설정하게 되면?
# docker run [-d] [--name 컨테이너명] [-v 컨테이너경로] [-e 환경변수=값] <이미지:태그>
docker run -d --name db -v /var/lib/mysql -e MYSQL_ROOT_PASSWORD=pass mysql:latestinspect로 컨테이너 조회하면 마운트 정보에 호스트 소스는 /var/lib/docker/volumes/uuid/_data에 저장된걸 확인할 수 있다.
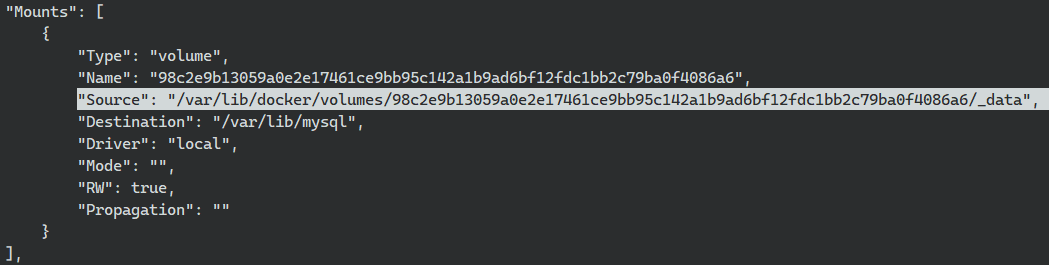
이 역시도 컨테이너를 삭제한 후에 데이터가 남는 걸 확인 할 수 있다.


5) docker volume 관리 명령어
- 볼륨 조회
docker volume ls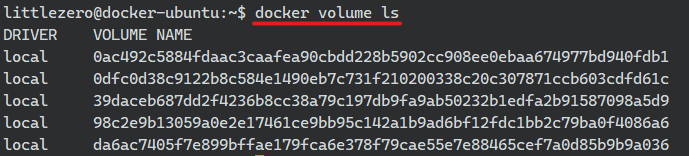
- 볼륨 제거
docker volume rm 볼륨UUID

2️⃣ 웹데이터 readonly 서비스로 지원하기
웹 컨텐츠를 생성하고 그걸 nginx로 운영하는 webserver로 서비스 할 수 있게 하는 실습
📢 여기서부터는 버츄얼박스와의 ip연결 문제로 이슈가 생겨서 wsl로 진행
1) 웹 컨텐츠 생성하기
폴더 하나 만들고 그 안에 단순 태그를 출력해 index.html을 하나 생성한다

2) 웹서버 서비스할 index.html을 호스트 파일로 교체
# docker run [-d] [--name 컨테이너명] [-v 호스트경로:컨테이너경로:읽기쓰기모드] /
# [-p 호스트포트:컨테이터포트] <이미지명:태그>
docker run -d --name web -v /webdata:/usr/share/nginx/html:ro -p 80:80 nginx:1.14
3️⃣ 컨테이너간 데이터 공유하기
디스크 사용량의 결과를 주기적으로 만들어내는 컨테이너를 만들어
* 디스크 사용량 모니터링
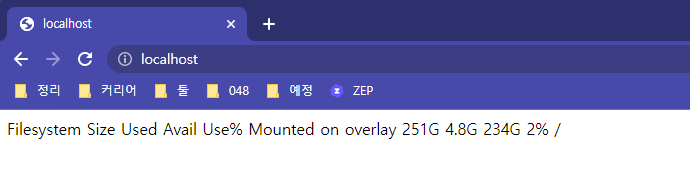
디스트 모니터링 할 때 사용하는 df 명령어 (disk free) 에 h옵션 (human/사람이 보기좋은 크기단위표시) 로 디스크 사용량을 모니터링
df -h /
🚩 일단 이걸 실습하기 위한 파일 생성
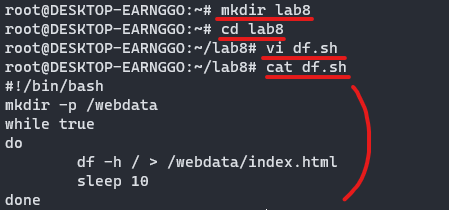
① mkdir로 lab8이라는 폴더 생성
② lab8로 이동
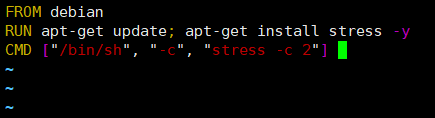
③ vi로 비쥬얼에디터 열어 df.sh 파일 생성
그 안에 쉘스크립트 내용을 작성
| 스크립트 | 설명 |
| #! /bin/bash | #!은 스크립트를 실행할 쉘을 지정하는 선언문 이 스크립트는 /bin/bash라는 bash쉘을 실행한다고 하는 것 |
| mkdir -p /webdata | mkdir(make directory)로 디렉토리 생성 p옵션 (parents)은 기존 디렉토리가 존재해도 에러가 발생하지 않고 필요경우 부모 디렉토리를 생성한다. |
| while true | 반복문으로 조건을 true로 했기에 무한 반복 |
| do | 반복될 부분의 시작 표시 |
| df -h / > /webdata/index.html | df 명령어로 (disk free) 디스크 사용량을 보며 h옵션(human)으로 사람이 보기 좋은 크기단위로 표시한다 > (리다이렉션)은 보통 command > filename과 같은 형태로 사용하며, 표준 입력을 전달 또는 표준 출력을 파일로 저장 따라서 디스크 사용량을 저 경로의 index.html파일로 저장한다는 뜻 |
| sleep 10 | 10초 일시정지 |
| done | 반복문 중 하나로 do와 짝을 이루어 반복될 부분 닫는 역할 |
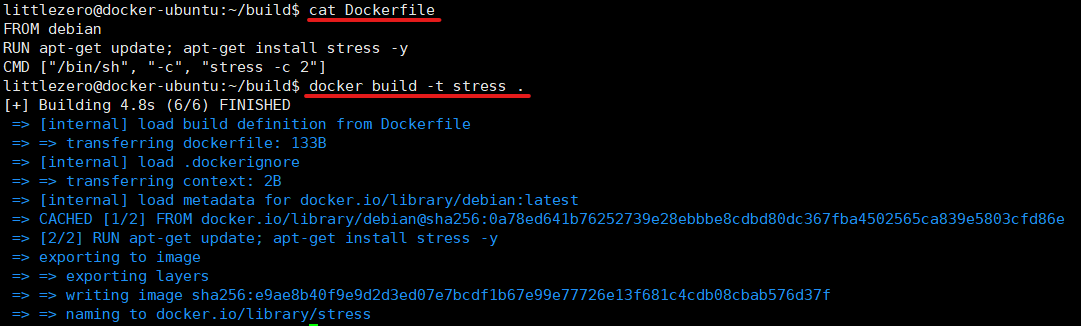
④ cat으로 df.sh 내용 다시 확인
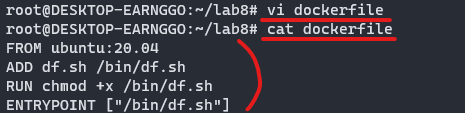
⑤ dockerfile도 vi로 생성하고 cat으로 확인
| 스크립트 | 설명 |
| FROM ubuntu:20.04 | 베이스이미지를 ubuntu:20.04에서 |
| ADD df.sh /bin/df.sh | 컨테이너 빌드시 호스트의 df.sh 파일을 컨테이너 /bin/df.sh로 복사 |
| RUN chmod +x /bin/df.sh | /bin/df.sh에 권한 설정하는 chmod (change mode) 명령어로 +x 속성(executable/실행가능) 을 주는 명령어를 실행 |
| ENTRYPOINT["/bin/df.sh"] | /bin/df.sh 실행 |
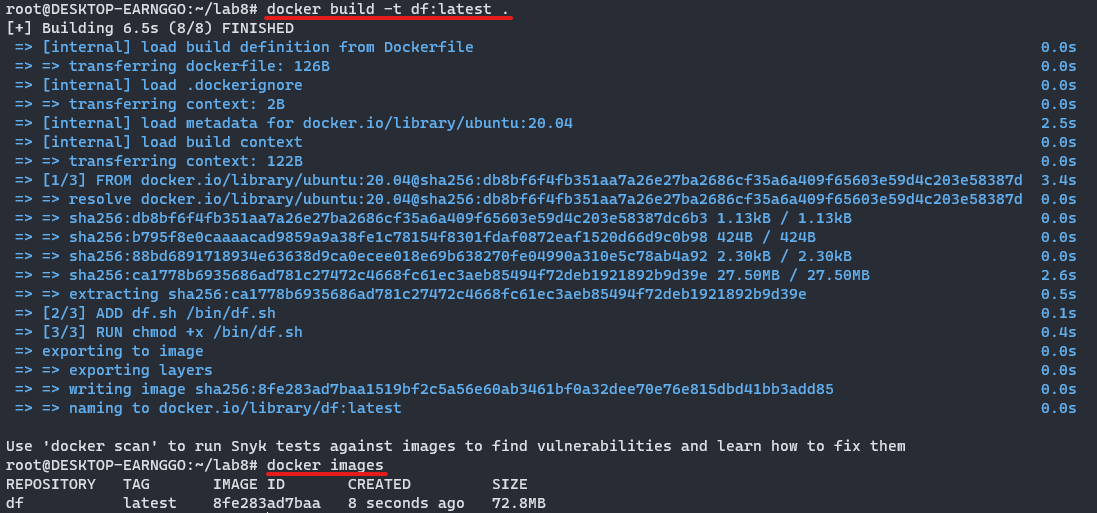
⑥ 도커 이미지 빌드 및 확인
🚩 생성한 파일과 이미지를 가지고 컨테이너를 돌려 아래 구조로 연결
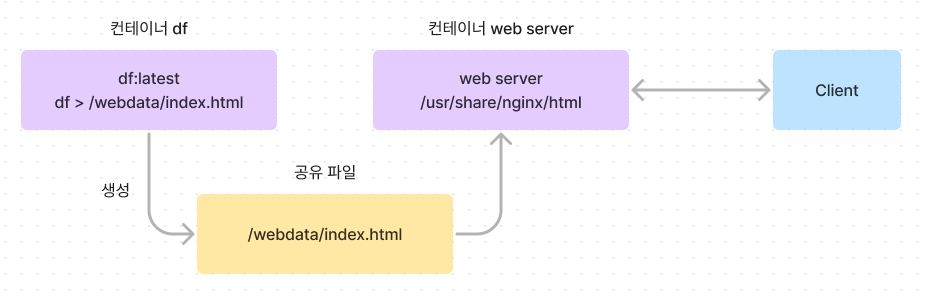
① index.html을 주기적으로 만드는 컨테이너 df 생성 및 실행
docker run -d -v /webdata:/webdata --name df df:latest② 생성된 index.html을 클라이언트로 연결할 web server 컨테이너 web 생성 및 실행
docker run -d --name web -v /webdata:/usr/share/nginx/html:ro -p 80:80 nginx:1.14③ 결과
'DevOps > Docker' 카테고리의 다른 글
| 따배도 도커 시리즈 10] 빌드에서 운영까지 (docker compose) (0) | 2023.04.23 |
|---|---|
| 따배도 도커 시리즈 9] 컨테이너간 통신(네트워크) (0) | 2023.04.23 |
| 따배도 도커 시리즈 7] 컨테이너 관리 (0) | 2023.04.15 |
| 따배도 도커 시리즈 6] 컨테이너 사용하기 (0) | 2023.04.14 |
| 따배도 도커 시리즈 5] 컨테이너 보관창고 Registry (0) | 2023.04.13 |