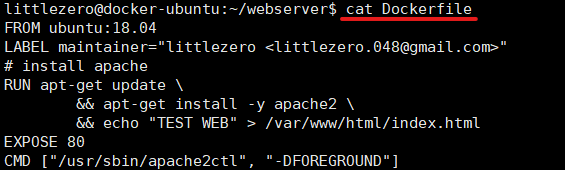
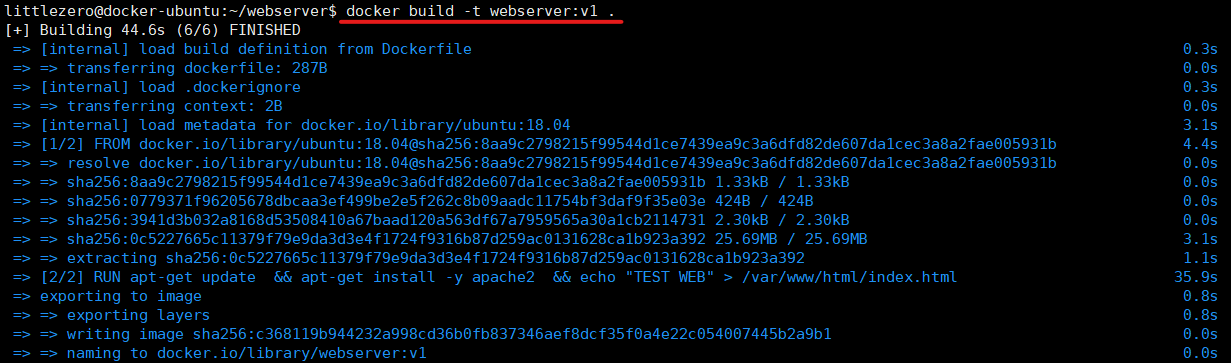
문제
📌 MySQL 로 풀이
📌 문제 링크 :
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
📌 문제 설명 :
2022년 1월의 도서 판매 데이터를 기준으로 저자 별, 카테고리 별 매출액(TOTAL_SALES = 판매량 * 판매가) 을 구하여, 저자 ID(AUTHOR_ID), 저자명(AUTHOR_NAME), 카테고리(CATEGORY), 매출액(SALES) 리스트를 출력하는 SQL문을 작성해주세요.
결과는 저자 ID를 오름차순으로, 저자 ID가 같다면 카테고리를 내림차순 정렬해주세요.
📌 테이블 :
다음은 어느 한 서점에서 판매중인 도서들의 도서 정보(BOOK), 저자 정보(AUTHOR) 테이블입니다.
BOOK 테이블은 각 도서의 정보를 담은 테이블로 아래와 같은 구조로 되어있습니다.
| BOOK_ID | INTEGER | FALSE | 도서 ID |
| CATEGORY | VARCHAR(N) | FALSE | 카테고리 (경제, 인문, 소설, 생활, 기술) |
| AUTHOR_ID | INTEGER | FALSE | 저자 ID |
| PRICE | INTEGER | FALSE | 판매가 (원) |
| PUBLISHED_DATE | DATE | FALSE | 출판일 |
AUTHOR 테이블은 도서의 저자의 정보를 담은 테이블로 아래와 같은 구조로 되어있습니다.
| AUTHOR_ID | INTEGER | FALSE | 저자 ID |
| AUTHOR_NAME | VARCHAR(N) | FALSE | 저자명 |
BOOK_SALES 테이블은 각 도서의 날짜 별 판매량 정보를 담은 테이블로 아래와 같은 구조로 되어있습니다.
| BOOK_ID | INTEGER | FALSE | 도서 ID |
| SALES_DATE | DATE | FALSE | 판매일 |
| SALES | INTEGER | FALSE | 판매량 |
풀이
추측)
일단 BOOK_SALES에서 2022년 1월 조회건 수만 출력하여 ROW수를 줄임
그 판매내역을 각각 BOOK_ID로 그룹화해 책마다의 판매고를 먼저 계산
그리고 나서 책정보와 작가 정보를 INNNER JOIN해서 연결하는 방식으로 하면 효율적일 듯 하다.
또, 전에 봤던 임시 테이블을 한번 적용해보면 좋을지도!
쿼리)
* 1차)
WITH S AS
(
SELECT BOOK_ID, SUM(SALES) AS SALES
FROM BOOK_SALES
WHERE SALES_DATE LIKE '2022-01%'
GROUP BY BOOK_ID
)
SELECT A.AUTHOR_ID, A.AUTHOR_NAME, B.CATEGORY, SUM(S.SALES * B.PRICE) AS TOTAL_SALES
FROM S
INNER JOIN BOOK AS B ON B.BOOK_ID = S.BOOK_ID
INNER JOIN AUTHOR AS A ON A.AUTHOR_ID = B.AUTHOR_ID
GROUP BY A.AUTHOR_ID, B.CATEGORY
ORDER BY A.AUTHOR_ID ASC, B.CATEGORY DESC
리뷰)
미리 테이블을 임시로 만들어 둠으로써 가독성이 굉장히 좋아졌다.
근데 임시 테이블이 성능적으로는 기존에 FROM안에 쓰는 것과 어떻게 다를까 싶어 찾아보니
이 임시테이블은 temp라는 임시 테이블에 저장되기 때문에 한번만 사용하는 테이블일 경우 오히려 오버헤드 요소!
임시테이블을 쓰는 것은 동일한 SQL이 반복되어서 사용될 때 성능을 높일수 있다.
이 점을 기억해서 사용하자!
'Coding Test > SQL' 카테고리의 다른 글
| Programmers] 조회수가 가장 많은 중고거래 게시판의 첨부파일 조회하기 (0) | 2023.04.17 |
|---|---|
| Programmers] 대여 횟수가 많은 자동차들의 월별 대여 횟수 구하기 (0) | 2023.04.16 |
| Programmers] 주문량이 많은 아이스크림들 조회하기 (0) | 2023.04.14 |
| Programmers] 취소되지 않은 진료 예약 조회하기 (0) | 2023.04.10 |
| Programmers] 년, 월, 성별 별 상품 구매 회원 수 구하기 (0) | 2023.04.08 |