캐시가 없을 때 ex) 이미지를 요청할 경우 서버는 이미지에 대한 헤더(0.1M)와 바디의 이미지(1.0M)를 합쳐 1.1M의 응답을 보낸다. 캐시가 없다면 요청할 때마다 1.1M의 응답을 보냄
데이터가 변경이 없어도 계속 네트워크를 통해 데이터를 다운받아야 한다.
인터넷 네트워크는 매우 느리고 비싸다 + 브라우저 로딩 속도가 느리다 = 느린 사용자 경험
캐시를 적용하면 ex) 서버에서 캐시 적용을 하게 되면 요청시 서버가 응답할 때 캐시가 유효한 시간을 지정하여 해당 요청에 대한 데이터를 보낸다. 그리고 웹브라우저는 그 응답 결과를 다운받아 브라우저 캐시에 저장한다 (유효시간만큼) 두번째 요청시 웹 브라우저는 캐시부터 뒤져서 유효시간이 만료되지 않았다면 존재하고 있을 데이터를 가져온다. 다시 요청시 유효시간 만료되면 다시 다운받아 기존에 캐시에 저장된 데이터를 초기화하고 가져온 것으로 덮는다.
비싼 네트워크 사용량을 줄일 수 있다.
캐시 가능 시간동안 네트워크를 사용하지 않아도 된다. + 브라우저 로딩 속도가 매우 빠르다 = 빠른 사용자 경험
만료되면 다시 조회하고 다시 다운로드하여 캐시를 갱신한다.
그런데 시간만 만료됬을 뿐 데이터가 변한건 아닌데 또 다운받아야 한다?! 이걸 해결할 수 있는 매커니즘이 바로 검증 헤더이다.
📍검증 헤더와 조건부 요청1
캐시 만료 후에도 서버에서 데이터를 변경하지 않았다면 만료됬더라도 그 캐시를 재사용 할 수 있다.
단, 웹브라우저 캐시의 데이터와 서버의 데이터가 같다는 사실을 확인할 수 있는 방법이 필요한데, 그게 검증 헤더.
클라이언트의 데이터 요청
검증 헤더를 통해 서버가 Last-Modified 값을 캐시 만료시간과 함께 전송 ex) Last-Modified: 2020년 11월 10일 10:00:00 (검증 헤더)
응답 결과를 웹브라우저가 캐시에 저장. (만료시간과 최종 수정일 정보 또한 같이)
클라이언트의 데이터 요청시 먼저 캐시를 조회하고 만료시간 초과한 경우 캐시의 최종 수정일을 요청에 넣어 보낸다. ex) if-modified-since: 2020년 11월 10일 10:00:00 (조건부 헤더, 만약 이후로 변경되었다면?)
서버가 이를 서버내의 최종 수정일과 비교해 봤을 때 동일하면 바디 없이 헤더 정보만 있는 304 Not Modified 응답을 보낸다. (헤더 크기 만큼의 용량은 전달) ex) cache-control: max-age=60 Last-Modified: 2020년 11월 10일 10:00:00
이 응답을 받으면 캐시 컨트롤 값을 갱신시켜 캐시를 다시 세팅. 그리고 이 캐시를 불러와 사용한다.
캐시 유효시간 초과 + 서버 데이터 갱신 없음 시
304 Moidified + 헤더 메타 정보만 응답(바디X)
클라이언트는 서버가 보낸 응답 헤더 정보로 캐시의 메타 정보를 갱신
클라이언트는 캐시에 저장되어 있는 데이터 재활용
결과적으로 네트워크 다운로드는 발생하나 용량이 적은 헤더만 다운받으므로 매우 실용적인 해결책이다.
📍검증 헤더와 조건부 요청2
검증 헤더
캐시 데이터와 서버 데이터가 같은지 검증하는 데이터
Last-Modified, ETag
조건부 요청 헤더
검증 헤더로 조건에 따른 분기
If-Modified-Since: Last-Modified 사용
If-None-Match: ETag 사용
조건이 만족하면 200 OK
조건이 만족하지 않으면 304 Not Modified
If-Modified-Since: 이후에 데이터가 수정되었다면?
데이터 미변경시 (실패) - 304 Not Modified, 헤더 데이터만 전송 (헤더 용량만큼 전송)
데이터 변경시 (성공) - 200 OK, 모든 데이터 전송 (헤더 + 바디 용량 전송)
Last-Modified, If-Modified-Since 단점
1초 미만(0.x초) 단위로 캐시 조정이 불가능 (최소 단위가 초라서)
날짜 기반의 로직 사용
데이터를 수정해서 날짜가 다르지만, 같은 데이터를 수정해서 데이터 결과가 똑같은 경우도 전체 다운로드
서버에서 최종 수정일이 아니라 별도의 캐시 로직을 관리하고 싶은 경우 사용 불가 (ex. 스페이스나 주석처럼 크게 영향이 없는 변경은 무시하고 캐시 유지 원하는 경우)
이런 경우 이걸 해결 할 수 있는 것이 ETag!
ETag, If-None-Match
ETag(Entity Tag)
캐시용 데이터에 임의의 고유한 버전 이름을 달아둠 (ex. ETag: "v1.0" , ETag: "a2jiodwjekjl3")
데이터가 변경되면 이 이름을 바꾸어서 변경 (Hash를 다시 생성, 만약 컨텐츠가 동일하면 동일한 Hash값 나옴)
요청시 ETag를 보내어 같으면 유지, 다르면 다시 다운로드
사용 과정은 Last-Modified, If-Modified-Since과 동일하며 실패시(미변경) 304 Not Modified, 성공시(변경) 200 OK
캐시 제어 로직을 서버에서 완전히 관리 (클라이언트는 캐시 매커니즘을 모른다)
클라이언트는 단순히 이 값을 서버에 제공
📍캐시와 조건부 요청 헤더 정리
캐시 제어 헤더
Cache-Control: 캐시 제어 (지금은 이걸로 모두 가능)
캐시 지시어(directives)
Cache-Control: max-age - 캐시 유효 시간, 초단위
Cache-Control: no-cache - 데이터는 캐시해도 되지만 캐시 사용하려고 할때 항상 Origin 서버에 검증하고 사용
Cache-Control: no-store - 데이터에 민감한 정보가 있으면 저장하면 안된다는 표시 (메모리에서 사용하고 최대한 빨리 삭제)
Pragma: 캐시 제어(하위 호환) : HTTP 1.0
Expires: 캐시 유효 기간(하위 호환)
캐시 만료일 지정
더 유연한 Cache-Control: max-age 권장
Cache-Control: max-age 랑 같이 사용시 Expires는 무시된다.
검증 헤더 (Validator)
ETag: "v1.0" , ETag: "a2jiodwjekjl3"
Last-Modified: Thu, 04 Jun 2020 07:19:24 GMT
조건부 요청 헤더
If-Match, If-None-Match: ETag 값 사용
If-Modified-Since, If-Unmodified-Since: Last-Modified 값 사용
📍프록시 캐시
원(Origin) 서버 원 서버에 직접 접근하게 되면 거리가 멀수록 속도가 느리다 이를 해결하기 위해 프록시 캐시 서버를 도입
프록시(Proxy) 캐시 서버 보통 CDN(Content Delivery Network)이름으로 서비스로 제공 원서버가 아닌 프록시 서버(클라이언트와 가까운 프록시 캐시 서버)에 거쳐 가게 하여, 프록시 서버에 캐시가 있으면 거기서 캐시를 조회해 빠른 응답을 받게 한다. (없으면 원서버 다녀와야함) - 프록시 서버의 캐시를 Public 캐시라 하고 클라이언트의 캐시는 Private 캐시라고 한다.
Cache-Control: 기타
Cache-Control: public - 응답이 public 캐시에 저장되어도 됨
Catche-Control: private - 응답이 해당 사용자만을 위한 것임, private 캐시에 저장해야 함(기본값)
Cache-Control: s-maxage - 프록시 캐시에만 적용되는 max-age
Age: 60 (HTTP 헤더) - 오리진 서버에 응답 후 프록시 캐시 내에 머문 시간(초)
📍캐시 무효화
확실한 캐시 무효화 응답이 존재 (캐시를 적용안해도 웹 브라우저가 임의로 캐시해버리고 하기 때문)
Cache-Control:
Cache-Control: no-cache, no-store, must-revalidate (이걸 모두 넣어주어야 무효화)
Cache-Control:no-cache - 데이터는 캐시해도 되지만 캐시 사용하려고 할때 항상 Origin 서버에 검증하고 사용
Cache-Control:no-store - 데이터에 민감한 정보가 있으면 저장하면 안된다는 표시 (메모리에서 사용하고 최대한 빨리 삭제)
Cahce-Control: must-revalidate - 캐시 만료후 최초 조회시 원 서버에 검증해야함 - 원 서버 접근 실패시 반드시 오류가 발생해야함 (504 Gateway Timeout) - must-revalidate는 캐시 유효 시간이라면 캐시를 사용함 - ❓no-cache가 있는데 이거 왜 사용 no-cache의 경우 프록시 서버와 원 서버 사이의 일시적 장애가 생긴 경우 프록시 서버의 오래된 데이터라도 보여주는 설정도 할 수 있다. must-revalidate는 서버 사이 장애시 무조건 504 오류 응답
Pragma: no-cache (HTTP 1.0 하위 호환, HTTP 1.0 요청 경우를 무효화 위해)
- General 헤더 : 메세지 전체에 적용되는 정보 ex) Connection: close - Request 헤더 : 요청 정보 ex) User-Agent: Mozilla/5.0 (Macintosh; ..) - Response 헤더 : 응답 정보 ex) Server: Apache - Entity 헤더: 엔티티 바디 정보 ex) Content-Type: text/html, Content-Length:3423
✅message Body
- 메시지 본문 (message body)은 엔티티 본문(entity body)을 전달하는 데 사용 - 엔티티 본문은 요청이나 응답에서 전달할 실제 데이터에 해당한다. 엔티티 본문을 메시지 본문에 담아 전송. - 엔티티 헤더는 엔티티 본문의 데이터를 해석할 수 있는 정보 제공 - 데이터 유형(html, json), 데이터 길이, 압축 정보 등등
2014년 RFC7230-7235 등장 - 스펙이 쪼개지면서 다수 개정 - 엔티티(Entity) 대신 표현(Representation) 요소가 도입 (완전 대응되는 건 X) - Representation (표현) = representation Metadata (표현 메타데이터(헤더)) + Representation Data (표현 데이터) - 이 REpresentation가 REST API의 RE에 해당 ✅ message Body
- 메시지 본문(message body)을 통해 표현 데이터 전달 - 메시지 본문 = 페이로드(payload) - 요청이나 응답에서 전달할 실제 데이터를 명확하게 표현으로 정의 - 표현 헤더는 표현 데이터를 해석할 수 있는 정보 제공 - 데이터 유형(html, json), 데이터 길이, 압축 정보 등등 - 참고: 표현 헤더는 표현 메타데이터와 페이로드 메시지를 구분해야 하지만, 여기 강의에선 생략
📍 표현
표현 : 클라이언트와 서버 간에 주고 받을 때는 서로가 이해할 수 있는 무언가로 변환해야한다. 그걸 위해 각자의 데이터를 html, xml, Json 등으로 표현하게 된다.
표현 헤더 (요청, 응답 둘 다 사용)
Content-Type: 표현 데이터의 형식 - 미디어 타입, 문자 인코딩 ex) text/html; charset=utf-8 , application/json , image/png 등
Content-Encoding: 표현 데이터의 압축 방식 - 데이터를 송신 측에서 압축 후 인코딩 헤더 추가 - 데이터를 수신 측에서 인코딩 헤더 정보로 압축 해제 ex) gzip , deflate , identity (No압축) 등
Content-Language: 표현 데이터의 자연 언어 - 자연 언어? 인간이 일상적으로 사용하고 있는 언어 ex) ko , en , en-US 등
Content-Length: 표현 데이터의 길이 - 바이트 단위 - Transfer-Encoding(전송 코딩)을 사용할 때는 Content-Length를 사용하면 안됨 (전송 코딩 안에 이미 정보가 다 들어 있다.)
📍콘텐츠 협상
협상 (콘텐츠 네고시에이션) : 클라이언트가 선호하는 표현이 이것이라고 서버에게 요청하는 것. 서버가 최대한 선호에 맞춰서 보내줄 수 있도록 한다. (못맞춰 줄 수도 있음) (협상헤더는 요청시에만 사용)
Accept : 클라이언트가 선호하는 미디어 타입 전달
Accept-Charset: 클라이언트가 선호하는 문자 인코딩
Accept-Encoding: 클라이언트가 선호하는 압축 인코딩
Accept-Language: 클라이언트가 선호하는 자연언어 - 협상 헤더 없는 경우 클라이언트 > 서버 : 클라이언트가 한국어 브라우저를 사용해서 서버에 요청 전송 서버 > 클라이언트 : 클라이언트의 선호 사항을 모름으로 그냥 서버의 기본으로 설정된 언어로 전송 - 협상 헤더 있는 경우 클라이언트 > 서버 : 클라이언트가 한국어 브라우저를 사용해서 서버에 요청 전송 서버 > 클라이언트 : 협상 헤더 Accept-Language: 로 ko(한국어)를 보내면 선호 언어로 전송 (그 언어 지원 경우)
❓그럼 독일어와 영어를 지원하는 서버에 한국어로 요청했는데... 독일어 보단 영어를 받고 싶다 이럴 때는? 그럴 때를 위한게 우선 순위 이다
협상과 우선순위
Quality Values(q) 값 사용 0~1, 클수록 높은 우선순위에 해당한다 (생략하면 1) ex) Accept-Language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7
ko-KR;q=1 (위에서는 q가 생략됨,ko-KR은 한국사람이 쓰는 한국어)
ko;q=0.9 (ko는 한국공통어)
en-US;q=0.8 (en-US는 US에서 쓰는 영어)
en:q=0.7 (en는 영어공통어)
구체적인 것이 가장 우선시 한다. ex)Accept: text/*, text/plain, text/plain;format=flowed, */*
순위: text/plain;format=flowed
순위: text/plain
순위: text/*
순위: */*
구체적인 것을 기준으로 미디어 타입을 맞춘다. ex) Accept: text/*;q=0.3, text/html;q=0.7, text/html;level=1, text/html;level=2;q=0.4, */*;q=0.5
Media Type
Quality
text/html;level=1
1
text/html
0.7
text/plain
0.3 (text/*에 맞춤)
image/jpeg
0.5 (*/*에 맞춤)
text/html;level=2
0.4 (얘는 왜 0.4 인가 하면 위에 text/html;level=2 에 대해서는 구체적인 우선순위가 나와있지만 아래 level=3는 정확히 매칭되는 것이 없어 text/html 의 우선순위에 맞춘 것)
text/html;level=3
0.7 (text/html 에 맞춤)
📍전송 방식
단순 전송: 요청하면 응답을 주는 데 Content-Length만 지정해서 콘텐츠를 그냥 주고 받는다. (Content-Length는 message body 전송시 기본인듯하다 분할 전송은 제외)
압축 전송: 서버가 콘텐츠를 압축하고 뭘로 압축했는지 정보를 Content-Encoding 헤더도 함께 보낸다.
분할 전송: Transfer-Encoding: chunked, chunk는 덩어리를 의미. 데이터를 분할해서 보낼거다 라는 표시를 하며 표시된 바이트 (여기서 5, 5, 0 에 해당하는 숫자들)의 Hello 데이터를 먼저 보내고, World를 보내고 \r\n(Enter, 끝이라는 뜻)을 보낸다. 주의) 분할 전송에서는 Content-Length를 보내면 안된다! Chunk안에 길이 정보 있다.
범위 전송: Range, Content-Range. 데이터의 범위를 지정해 전송 받을 수 있다. 파일을 받다가 끊겼을 때 이미 받아진 걸 제외한 걸 받고자 할 때 사용가능
📍일반 정보
From: 유저 에이전트의 이메일 정보 - 일반적으로 사용X, 검색 엔진 같은 곳에서 사용 - 요청에서 사용
Referer: 이전 웹 페이지 주소 - 현재 요청된 페이지의 이전 웹 페이지 주소 - A > B로 이동하는 경우 B를 요청할 때 Referer: A 를 포함해서 요청한다. - Referer을 사용해 유입 경로 분석 가능하다. - 요청에서 사용 - 😯❓황당하게도 Referer은 Referrer의 오타인데 이미 너무 많이 사용해서 그대로 사용하는 거라고
User-Agent: 유저 에이전트 애플리케이션 정보 - ex)user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 - 클라이언트의 애플리케이션 정보 (웹 브라우저 정보 등) - 통계 정보로 사용, 어떤 종류의 브라우저에서 장애가 발생하는 지 파악 가능 - 요청에서 사용
Server: 요청을 처리하는 오리진 서버의 소프트웨어 정보 (중간의 정보가 거치는 서버들이 아니라 정보를 처리하는 끝점에 있는 서버를 오리진 서버라고 한다.) - ex) Server: Apach/2.2.22 (Debian) - ex) server: nginx - 응답에서 사용
Date: 메시지가 생성된 날짜 - ex) Date: Tue, 15 Nov 1994 08:12:31 GMT - 응답에서 사용
📍특별한 정보
Host: 요청한 호스트 정보 (도메인) - 필수값 - 요청에서 사용 - 하나의 서버가 여러 도메인을 처리해야 할 때, 하나의 IP 주소에 여러 도메인이 적용되어 있을 때 (가상호스트를 통해 서버에 여러 애플리케이션 여러개가 구동 중일 경우 클라이언트에서 어느 도메인으로 데이터가 가야할지 모르기 때문에 이를 통해 구분) ? 포트랑 어떻게 다르지? TCP/IP는 IP로만 통신? 포트는?
Location: 페이지 리다이렉션 - 웹 브라우저 3xx 응답의 결과에 Location 헤더가 있으면, Location 위치로 자동 이동(리다이렉트) - 201 (Created): Location 값은 요청에 의해 생성된 리소스 URI로 응답시 함께 전달 - 3xx (Redirection): Location 값은 요청을 자동으로 리다이렉션하기 위한 대상 리소스를 가르킴
Allow: 허용 가능한 HTTP 메서드 - 405 (Method Not Allowed) 에서 응답에 포함해야함 - Allow: GET, HEAD, PUT - ex) 만약 경로가 존재하고 GET, HEAD, PUT만을 허용하는데 POST로 요청한 경우 위와 같이 응답
Retry-After: 유저 에이전트가 다음 요청을 하기까지 기다려야 하는 시간 - 503 (Service Unavailavble): 서비스가 언제까지 불능인지 알려줄 수 있음 - ex) Retry-Ater: Fri, 31 Dec 1999 23:59:59 GMT (날짜 표기) - ex) Retry-Ater: 120 (초단위 표기)
📍인증
Authorization: 클라이언트 인증 정보를 서버에 전달 - ex) Authorization: Basic xxxxxxxxxxxxxxx - 다양한 인증 메커니즘 마다 value가 달라짐
WWW-Authenticate: 리소스 접근시 필요한 인증 방법 정의 - 접근시 인증이 안됬거나 문제시 401 Unauthorized 응답과 함께 사용, 아래처럼 필요한 인증 정보의 예시를 함께 보내준다. - WWW-Authenticate: Newauth realm="apps", type=1, title="Login to \"apps\"",Basic realm="simple"
📍쿠키
Set-Cookie: 서버에서 클라이언트로 쿠키 전달 (응답)
Cookie: 클라이언트가 서버에서 받은 쿠키를 저장하고, HTTP 요청시 서버로 전달
* 쿠키 등장
HTTP는 무상태 프로토콜이다. 요청과 응답을 받고 나면 끊어져 서로 상태를 유지하지 않기 때문에 로그인 한 상대라는 걸 알 수 있는 방법이 서버에겐 없다.
하지만 로그인 상태를 유지해야한다면 대안은?
모든 요청에 사용자 정보를 포함해서 전송 - 보안문제부터 데이터 전송량이 늘고, 개발 어려움 등의 다양한 문제 발생 - 브라우저를 완전히 종료하고 다시 열면 그 땐 또 어떻게 해야하는 지 등의 문제 발생
이걸 해결하기 위해 쿠키라는 개념이 도입됨
*쿠키 저장과 전달 과정
로그인을 하게 되면 서버에서 Set-Cookie에 로그인 유저 정보를 말아서 보낸다. (왜 만다라는 표현을 할까?)
웹브라우저는 이를 받아 웹브라우저 안의 쿠키 저장소에 그 정보를 저장해 놓는다.
이제 웹브라우저는 해당 서버에 요청할 때 마다 쿠키 저장소를 뒤져서 쿠키 값을 가져와 헤더에 Cookie 값으로 전달한다.
*쿠키는 모든 요청에 쿠키 정보를 자동 포함한다.
하지만 정말 모든 요청에 보내면 이는 또 다른 문제가 발생한다. (따라서 따로 제약하는 방법도 있다)
네트워크 트래픽이 추가로 유발되기 때문에 최소한의 정보(세션 ID, 인증토큰 등)만 사용해야 한다.
보안에 민감한 데이터는 저장하면 안된다. - 서버에 전송하지 않고 웹 브라우저 내에만 저장하고 싶다면 웹 스토리지 참고
HTTP/1.1 200 OK Content-Type: application/json Content-length: 34
{ "username" : "young", "age" : 20 }
1xx (Informational) : 요청이 수신되어 처리중
2xx (Successful) : 요청 정상 처리
3xx (Redirection) : 요청을 완료하려면 추가 행동이 필요
4xx (Client Error) : 클라이언트 오류, 잘못된 문법 등으로 서버가 요청을 수행할 수 없음
5xx (Server Error) : 서버 오류, 서버가 정상 요청을 처리하지 못함
처음 보는 상태 코드가 있다?
클라이언트가 인식할 수 없는 상태코드를 서버가 반환하게 되면 클라이언트는 상위 상태코드로 해석해 처리하게 된다. 그래서 새로운 상태 코드가 추가 되더라도 클라이언트를 변경하지 않아도 된다. (ex. 299 ??? > 2xx (Successful))
📍1xx (Informational)
거의 사용하지 않으므로 생략
📍2xx - 성공
클라이언트의 요청을 성공적으로 처리
200 OK : 요청 성공
201 Created : 요청 성공해 새로운 리소스가 생성됨, 생성된 리소스는 Location 헤더 필드로 식별
202 Accepted : 요청 접수되었으나 처리는 미완료. 배치 처리 등에 사용. ex) 접수 뒤 1시간 뒤 배치 프로세스가 처리
204 No Content : 요청을 성공적으로 수행했으나 응답 페이로드 본문에 보낼 데이터 없음
결과 내용이 없어도 204 메시지(2xx)만으로 성공을 인식
ex) 웹 문서 편집기의 save 버튼 : 버튼 결과로 아무 내용 없어도 된다. 버튼을 눌러도 같은 화면을 유지해야 한다. 드의 경우
📍3xx - 리다이렉션
요청을 완료하기 위해 유저 에이전트의 추가 조치 필요
웹브라우저는 3xx 응답 결과에 Location 헤더가 있으면 해당 위치로 자동 이동(리다이렉트)한다.
300 Multiple Choices : 사용안함
301 Moved Permanently
302 Found
303 See Other
304 Not Modified
307 Temporary Redirect
308 Permanent Redirect
리다이렉션 흐름
리다이렉션의 종류
영구 리다이렉션 - 특정 리소스의 URI가 영구적으로 이동 (ex. /members > /users)
원래 URL 사용하지 않으며 검색 엔진 등에서도 변경을 인지한다.
301 Moved Permanently : 리다이렉트시 요청 메서드가 GET이 될 수도 있고, 본문이 제거될 수도 있다 (모호함)
308 Permanent Redirect : 301과 기능이 같으나 처음의 요청 메서드와 본문이 유지 된다
일시 리다이렉션 - 일시적인 잠깐 이동 (ex. 주문 완료 후 주문 내역화면으로 이동. PRG패턴)
실무에서 많이 사용하는 방식
리소스 URI가 일시적으로 변경하기 때문에 검색 엔진 등에서 URL을 변경하면 안된다.
302 Found: 리다이렉트시 요청 메서드가 GET으로 변할 수 있고, 본문이 제거될 수도 있다. 모호하다.
303 See Other: 302와 기능은 같고 리다이렉트 요청 메서드가 GET으로 변경 (302가 기능 스펙에 대해 모호한 부분이 있다면 303은 확실하게 GET 메서드로 사용한다)
307 Temporary Redirect:302와 기능은 같으나처음의 요청 메서드와 본문이 유지 된다 (요청 메서드 변경하면 안됨)
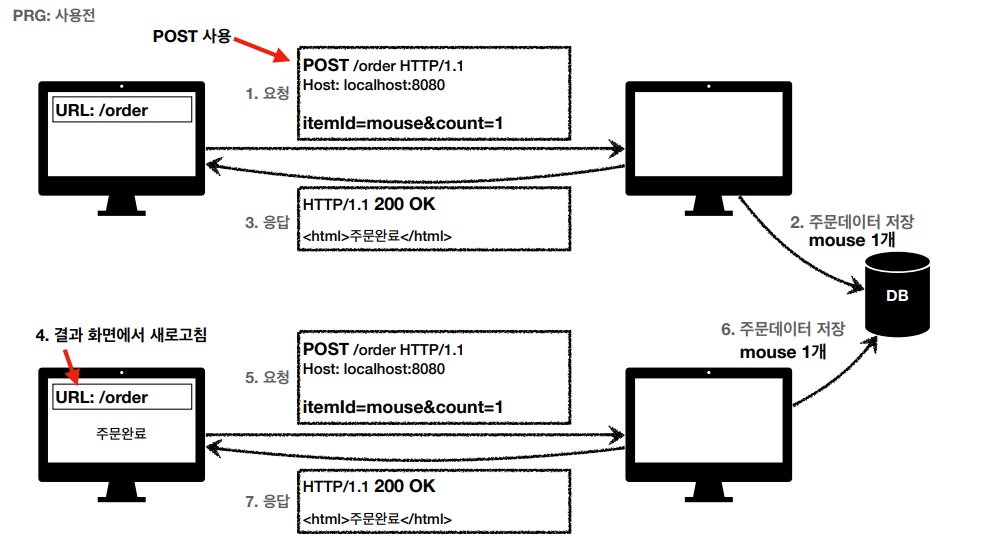
일시적 리다이렉션을 언제 쓸까? PRG패턴 (Post Redirect Get) : Post로 주문 후 새로고침할 경우 주문을 재요청하게 되여 중복 주문이 생길 수 가 있다. 이때 post로 주문하고 주문 결과 화면을 get으로 리다이렉트 하게되면 새로고침해도 결과 화면을 get요청하게 되니 중복을 피할 수가 있다. PRG 사용전 새로고침하면 order가 재요청되어 5번 발생PRG 사용후 새로고침하면 했을 때는 주문 결과 화면을 GET요청하게 되어 중복 주문 방지